컴퓨터 비전을 활용한 자율주행용 차량 3차원 분석을 위한 데이터셋 소개
작성자 : 백승렬 울산과학기술원 인공지능대학원 교수 2022.12.21 게시서론
자율 주행은 산업계와 학계 모두에서 주목을 받고 있다. 도로에서 움직이거나 주차된 차량의 3차원 속성 (예: 변환, 회전 및 모양)을 추정하는 것은 자율 주행을 위한 중요한 작업인 반면, 컴퓨터 비전 커뮤니티에서 아직 활발히 연구되고 있지 않다. 이는 대표적으로 자율 주행 연구에 적합한 대규모 데이터셋이 아직 구축되어 있지 못하기 때문이다. 자율 주행 관련 데이터셋은 부분적으로는 3차원 정답이 존재하지만 아직 완전하지 못하다. 본고에서는 자율주행 응용분야에 딥러닝에 기반한 컴퓨터 비전 기술을 적용하기 위한 대규모 3차원 자동차 데이터베이스들 [1-8]을 살펴보고자 한다.
KITTI 데이터셋 [1]
1대의 카메라와 스테레오 (stereo) 카메라, 3차원 레이저 스캐너, GPS/IMU 탐지 시스템 등을 그림 1과 같이 차량 내외부에 장착하고, 총 6시간 분량의 실제 교통 상황을 촬영한 데이터셋이 최초로 수집되었다. 3차원 박스 형태의 정답들이 영상마다 매겨지게 되었고, 각 3차원 박스 형태의 정답은 차(car), 밴(van), 트럭(truck), 보행자(pedestrian), 앉아있는 사람 (sitting person), 자전거 타는 사람(cyclist), 트램(tram), 기타(트레일러 등)에 대한 클래스 정보를 가지도록 정답이 제공되었다. 총 7,481장의 영상이 수집되었고, 한 영상에 대략 4.8개의 개체가 존재하는 영상들이 취득되었다. 한 영상에 존재하는 최다 차량의 숫자는 14대였고, 차종은 총 16개가 모였다.
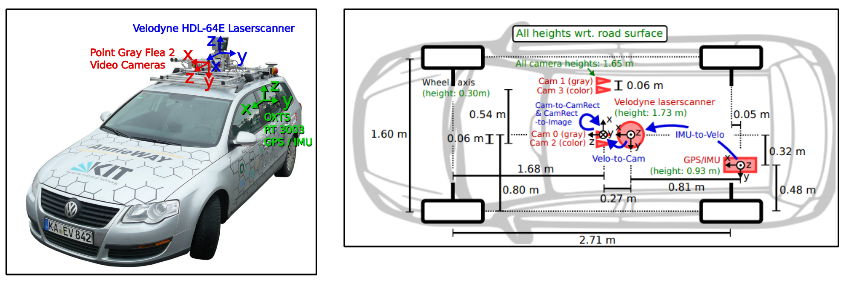
그림1. KITTI 데이터셋 수집을 위한 센서 배치
Vision meets Robotics: The KITTI Dataset, IJRR 2013.
PASCAL3D+데이터셋 [2]
기존 PASCAL VOC 2012 데이터셋에 존재한 12개 물체 종류 (사람, 자동차 등) 에 대하여 3차원 정답을 제공하는 데이터셋이다. 약 3000개 이상의 물체에 대해 영상과 정답이 취득되어져서 기존 데이터셋에 비해 다양한 종류의 물체에 일반화 능력을 가지게 될 수 있으며, 실외에서만 취득된 KITTI 데이터셋 [1]과 달리 실내외 모두에서 취득되었다. 그림2는 PASCAL 3D+ 데이터셋이 가지고 있는 영상과 3차원 모델 정답에 대한 예시를 보여주고 있다.
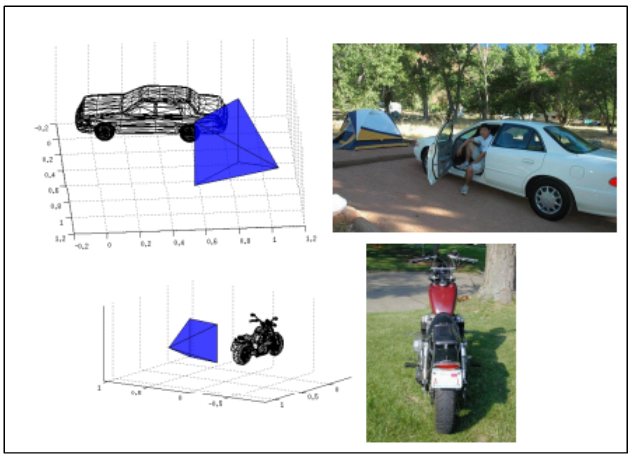
그림2. PASCAL 3D+ 데이터셋이 가지고 있는 영상과 3차원 모델 정답에 대한 예시
Beyond PASCAL: A Benchmark for 3D Object Detection in the Wild, WACV 2014.
ApolloCar3D 데이터셋 [3]
[3] 논문에서는 5277개의 운전 영상을 포함하고 있고, 총 60,000개 이상의 자동차 인스턴스를 포함한다. 이 데이터셋의 영상에 존재하는 차들은 3차원 CAD 모델을 가지고 있으며 또한 이 모델들은 실제 차량 사이즈를 가지고 있다. 그리고 3차원 키 포인트들에 대한 정답도 가지고 있다. 그림 7에서 조금 더 많은 데이터셋과 비교를 수행하고 있다. 기존 PASCAL 3D+ [2] 혹은 KITTI 데이터셋 [1]보다 20배 이상 크기가 커서 딥러닝 기술에 활용될 수 있다. 또한 KITTI와 PASCAL3D+ 데이터셋은 3차원 키포인트에 대한 정답을 보유하고 있지 않은 반면, ApolloCar3D 데이터셋은 차에 대한 66개의 키포인트를 가지고 있다. 데이터셋에 존재하는 영상은 총 5천장 정도로 다른 데이터셋과 비슷한 크기이지만 한장에 포함된 차의 갯수는 평균 11~12개 정도로 1-2개 정도를 포함하거나 많아야 5개 정도가 존재하는 기존 데이터셋에 비해 많은 편이다. 또한 ApolloCar3D 데이터셋은 기존 데이터셋 대비 3배 이상의 차종을 포함하고 있다 (79대 vs. 다른 데이터셋의 평균 차종은 10~20대 수준). 또한 차들은 더 먼 거리에서 촬영이 되었고, 물체 등에 가림현상이 있도록 촬영이 되었다. 또한 차들은 다양하게 길 위에 분포하고 있어 본 데이터를 활용하여 학습시 조금 더 어려운 장면에 대하여 잘 동작할 가능성이 있다. 차종은 다양한 종이 있지만 세단이 가장 많이 분포되어 있고, 대부분의 차가 정면을 바라보거나 뒷면을 바라보고 있는 분포로 되어 있다. 대부분의 영상이 10개 이상의 물체를 포함하고 있다. 또한 3차원 키포인트는 그림3과 같이 정의된다. 그림3의 1번부터 66번까지의 점이 각각의 키포인트를 의미하며 본 데이터셋은 이들 66개 점에 대한 3차원 좌표에 대한 정답을 가지고 있다.
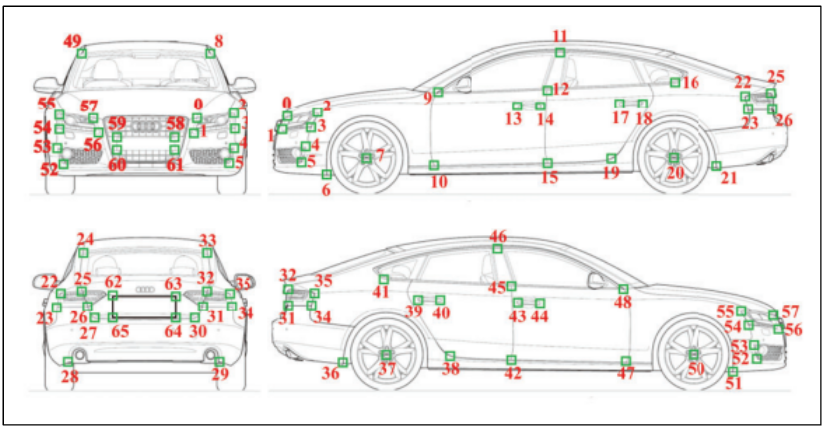
그림3. 차량 키포인트
ApolloCar3D: A Large 3D Car Instance Understanding Benchmark for Autonomous Driving, CVPR 2019.
nuScenes 데이터셋 [4]
본 데이터셋은 LiDAR 센서등 다양한 센서를 활용하여 자율주행 환경에서 3차원 정답을 자동으로 취득한 최초의 데이터셋이다. 총 6개의 카메라, 5개의 레이더 센서, 1개의 LiDAR 센서를 활용하여 360도 촬영을 수행하였다. 총 1000개의 scene을 포함하고 있고, 각각이 20초 정도 분량의 동영상으로 되어 있다. 또한 23개 클래스와 8개 속성을 가지는 3차원 박스가 정답으로 제공된다. KITTI 데이터셋 [1]에 비하여 7배 많은 정답과 100배 많은 영상량을 가지고 있다. 컬러 영상은 14만 정도 가지고 있고, 3차원 정답이 있는 프레임들은 4만장 정도에 가깝다. 밤과 비오는 환경에서도 촬영된 영상이 있다. 모아진 1000개의 배경들은 교차로, 공사현장 등 차가 붐비는 상황과 응급상황, 동물 출현 등의 차가 없는 상황, 또한 위험한 보행자가 나타난 상황, 차선변경, 유턴, 멈춤 등과 같은 주행상황을 다양하게 포함하고 있다. 그림 4는 nuScene데이터셋을 촬영하고 3차원 정답을 얻기 위한 센서들의 차량 내 배치를 나타낸다. 카메라는 12Hz, 레이더는 13Hz, 라이더는 20Hz의 주파수로 캡쳐를 수행해서 고품질의 데이터 수집이 가능하다.
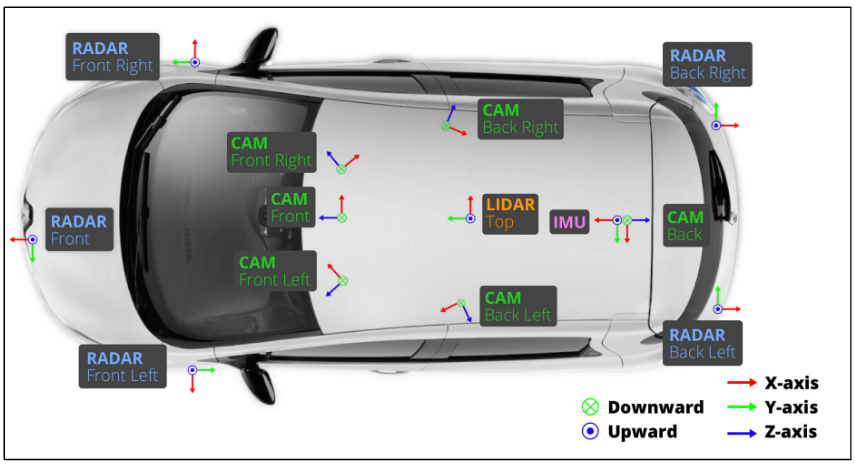
그림4. nuScenes 데이터셋을 수집하기 위한 차랑내외 센서 위치
nuScenes: A multimodal dataset for autonomous driving, CVPR 2020.
Waymo Open 데이터셋 [5]
Google의 자율주행 자회사 Waymo에서 공개한 데이터셋으로 총 1,150개의 데이터로 이루어져 있다. 잘 동기화되고 보정된 고품질 LiDar 및 카메라로 구성된 각각 20초로 구성된 장면이 촬영되어 있으며, 다양한 도시 및 교외 지역에서 수집된 데이터로 되어 있다. 제안된 지리를 담고 있으며 기존 데이터셋에 비해 배경에 대한 다양성이 약 15배 정도 높다. 그림 5와 같이 총 4개 물체 (차량, 보행자, 신호 및 자전거 탄 사람)에 대한 3차원 레이블들이 정답으로 매겨져 있으며, 데이터셋은 http://www.waymo.com/open 웹 사이트에 공개되어 있다. 3차원 박스들은 사람 손으로 레이블링이 되었으며 LiDar 카메라용은 3차원 박스로 되어 있고, 일반 카메라용은 2차원 박스로 레이블링 되어 있다. 1,200만 개에 육박하는 박스가 레이블링이 되어 있고, 11만 3천개 가량의 물체들이 레이블링 되어 있다. 모든 레이블들은 상품화 가능한 신뢰성 있는 툴을 이용해 레이블링 되었다.
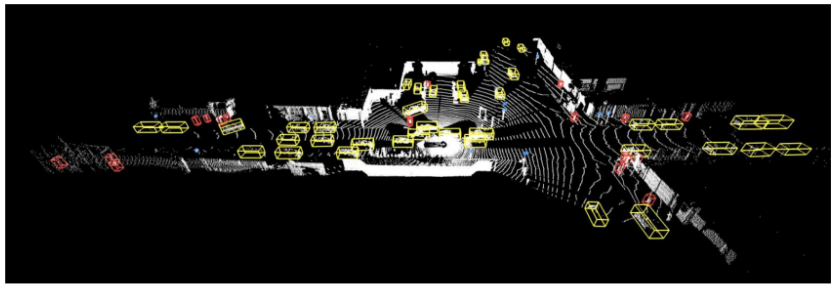
그림5. Waymo Open 데이터셋의 LiDAR 영상과 3차원 정답 예시
Scalability in Perception for Autonomous Driving: Waymo Open Dataset, CVPR 2020.
BDD100K 데이터셋 [6]
BDD100K 데이터셋은 10만개의 비디오와 10개 종 이상의 정답을 가지는 대규모 비디오 데이터셋이며, 자율주행 환경에서 촬영되었다. 그림 6과 같이 다양한 날씨환경, 시간, 배경(scene)에서 촬영되었고, 배경에 대한 정답, 물체에 대한 박스, 차선, 운전가능한 영역, 물체에 대한 픽셀 레벨의 정답 등으로 총 10개 종류 이상의 정답들이 구성되어 있다. 720p 사이즈의 고해상도 영상들로 구성되어 있고, 30Hz이상의 주파수로 촬영되었으며 GPS/IMU 센서도 가지고 촬영되었다. 또한 각각의 비디오들은 40초 정도로 구성되어 있다. 뉴욕, 샌프란시스코 등을 포함해 다양한 도시, 주거지역, 고속도로 등 도로 환경에서 촬영되었다.

그림6. BDD100K 데이터셋의 영상 예시
BDD100K: A Diverse Driving Dataset for Heterogeneous Multitask Learning , CVPR 2020.
ONCE 데이터셋 [7]
본 데이터셋은 100만개의 LiDAR 장면과 700만 개의 컬러 영상을 가지고 있으며 총 144 운전 시간 중 선택되었다. 이것은 nuScenes과 Waymo 데이터셋보다 20배 정도 더 길다. 또한 총 백만개 정도의 scene을 포함하여 23만개 정도의 scene을 포함하는 Waymo 데이터셋과 40만개 정도의 scene을 포함하는 nuScenes 데이터셋보다 다양한 scene을 포함하고 있다. 다양한 지역과 기간 및 다양한 범위에서 수집되어 학습되는 모델의 일반화 능력을 높이려 하였다. 그림3은 Waymo, nuScenes, BDD100k 데이터셋에 비하여 다양한 시간, 날씨, 장소에서 ONCE 데이터셋이 취득되었음을 보여준다. 언급한 세가지 데이터셋은 저녁에 대한 분포가 상대적으로 낮은데 반해 ONCE 데이터셋은 저녁에 취득된 영상의 비율이 잘 균형을 이루고 있다.
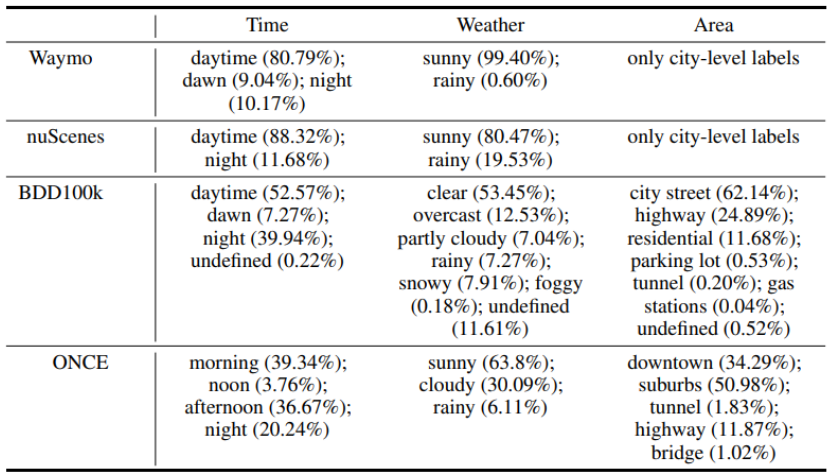
그림7. 이전 데이터셋과 ONCE 데이터셋의 비교
One million scenes for autonomous driving: Once dataset, NeurIPS 2021.

그림8. ONCE 데이터 셋의 영상 및 정답 예시
One million scenes for autonomous driving: Once dataset, NeurIPS 2021.
Rope3D 데이터셋 [8]
논문에서는 자율 주행 데이터셋들이 보통 정면 카메라 시점에 국한된다는 점에 착안하여, 여러 시점에서의 영상을 제공하며 그동안 간과되었던 길가(roadside) 인식 작업에도 활용될 수 있는 데이터셋을 수집하였다. 해당 데이터셋은 총 5만장의 영상을 포함하며 150만개 이상의 3차원 객체를 포함한다. 또한 라이더 센서를 이용하여 3차원 정답도 정확하게 제공하고 있다. 150만여개의 3차원 박스 정답을 제공하고 컬러영상의 해상도는 1920x1080급의 고해상도 영상을 제공한다. 또한 비오는 환경, 밤, 새벽 등의 다양한 날씨 환경에서 촬영되어 학습되는 모델이 일반화 능력을 가질 수 있게 하고 있다. 3차원 박스는 차(car), 트럭(truck), 밴(van), 버스(bus), 보행자(pedestrian), 자전거 타는 사람(cyclist), 오토바이타는 사람(motorcyclist) 등으로 구분되어 총 12개의 의미적 클래스로 구성되어 있다. 그림 9에서 그림 (a)는 정면 뷰에서 찍힌 영상들을 나타내며, (b)는 길가(roadside) 시점에서 찍힌 영상들을 나타낸다. 삼각형 표시는 LiDAR 카메라를 장착한 같은 차를 나타낸다.
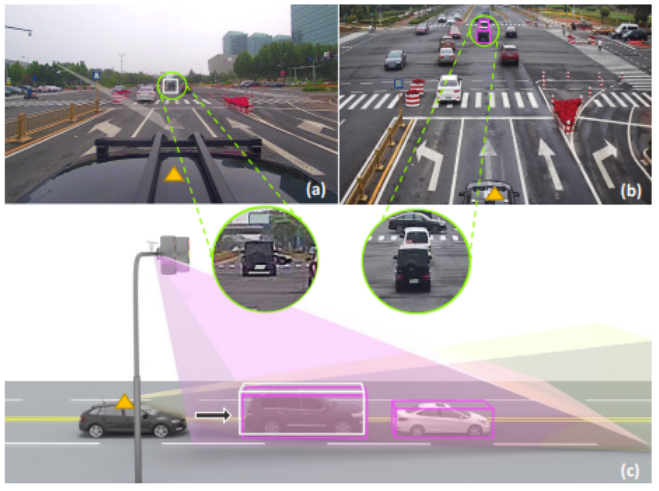
그림9. Rope 3D 데이터셋의 영상 예시
Rope3D: The Roadside Perception Dataset for Autonomous Driving and Monocular 3D Object Detection Task, CVPR 2022.
결론
자율주행을 위한 데이터셋은 그 양과 다양성 및 정답의 정확성에 있어 지속적으로 발전 중이며, 이러한 데이터셋을 활용하여 딥러닝 모델을 학습할 경우, 사람의 인식능력에 가까운 자율주행 자동차의 개발이 가능할 것이라고 예상된다. 근 시일내에 사람의 도움없이 운전 가능한 완전 자율 자동차 시장이 도래하길 기대한다.
본 사이트(LoTIS. www.lotis.or.kr)의 콘텐츠는 무단 복제, 전송, 배포 기타 저작권법에 위반되는 방법으로 사용할 경우 저작권법 제 136조에 따라 5년 이하의 징역 또는 5천만원 이하의 벌금에 처해질 수 있습니다.
| 집필진 | ||